
The Assignment
Let’s say you are tasked to write a service that handles user registration. Upon registration, two emails will be sent out — one welcome email, and another for confirming the email. How would you design it?
Dissecting the Problem
Surely it’s not difficult. All we need is just one register function that persists the user, and sends email right? You might be tempted to do so:
While the solution is straightforward, it lacks the following:
- reliability: If the first email fails to send, how do we retry it? If the second fails, how do we retry it without double-sending the first.
- extensibility: What if we have additional requirements after the user is created? Adding new lines of code means more room for failure in between.
In short, we want to be able to repeat the delivery of the email, but at the same time deliver it only once.
Investigating Alternatives
Create the user, and then publish the event
Here’s another variation, but in the context of event-driven design where an event is published to consumers:
However, many things can still go wrong here:
- The server crashed or restarted.
- The message broker may not be available, crashed, or restarted.
- The code that publishes the event failed due to an error.
All of this leads to the fact that a user may be created, but the message could not be delivered and is lost.
Publish the event first, then create the user
Reversing the steps (publishing the event, and then creating the user) would not help either:
Now we need to deal with the following problems:
- Incomplete information like user id. We can generate one on the client-side, but there’s no guarantee it is unique in the database.
- Publishing the event might be successful, but the creation of the user in the database might fail, leaving the system in an incomplete state. The published event would not be able to query the user later.
Create the user and publish it in a transaction
Putting the operation in a transaction, hoping that the whole operation would be reverted if the publishing fails does not help either:
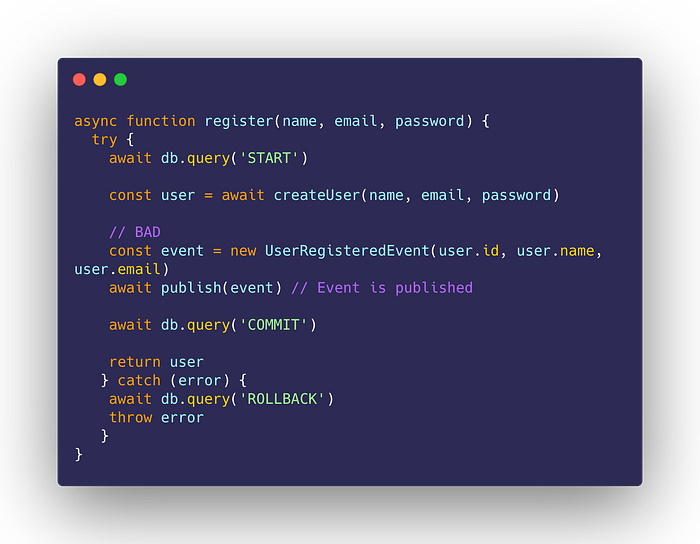
It is easy to imagine that the operation above is executed serially, but it is not. This is always a trap, especially when dealing with external infrastructure.
- If the event is published successfully and is picked up by a worker before the transaction is committed, the worker might not be able to query the user for processing. Sure, we can retry them, but at the cost of false-positive errors.
- If the publish takes a long time, the transaction will be open for a long time, slowing performance.
- Complexity increases in the scenario where there are more intermediate steps and multiple events to be published.
Implementing the Outbox Pattern
The Outbox Pattern solves the problem above by persisting the event in the same transaction:
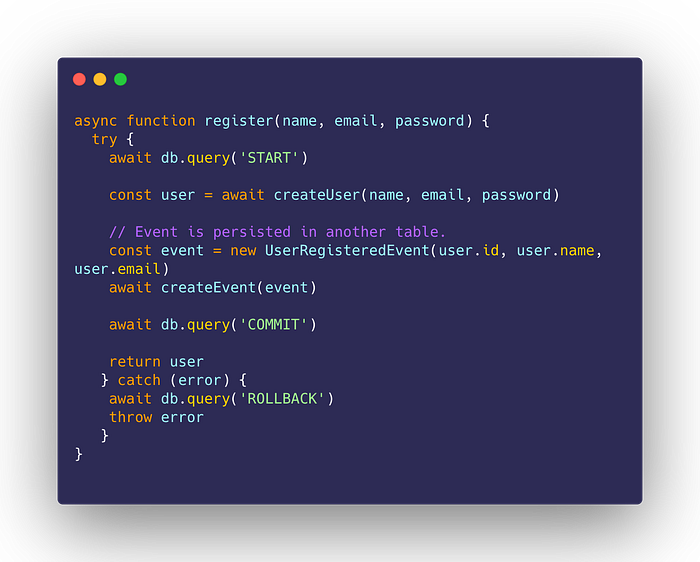
With this, both operations are atomic — they succeed together, or fail as a whole. To publish the event, we have another function running in the background that will periodically pull the unprocessed events from the database:
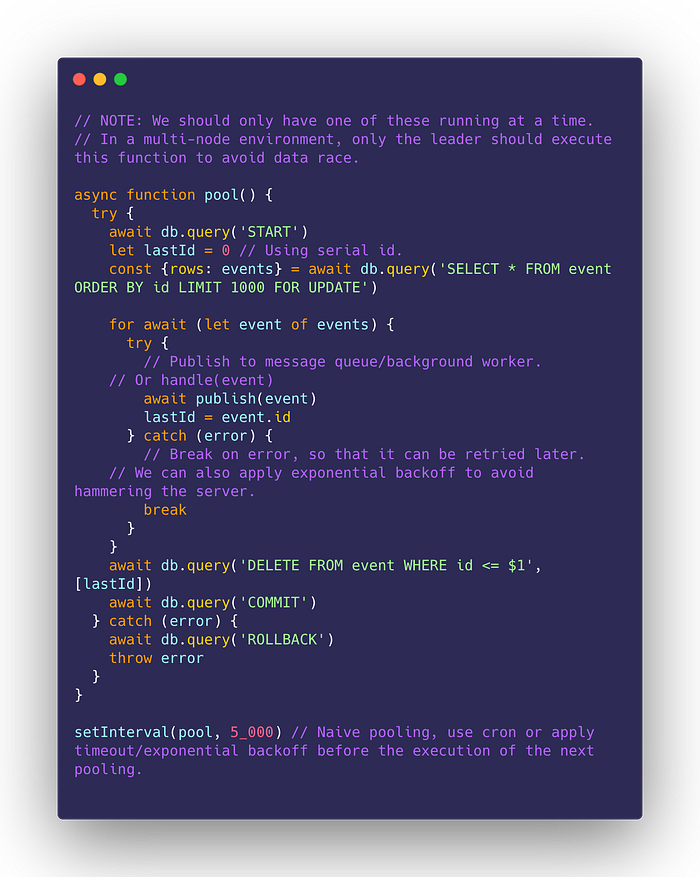
Basically, the pool does the following:
- query unpublished/unhandled events
- publish/handle that event
- delete the events from the table
- repeat at every interval
How about database trigger?
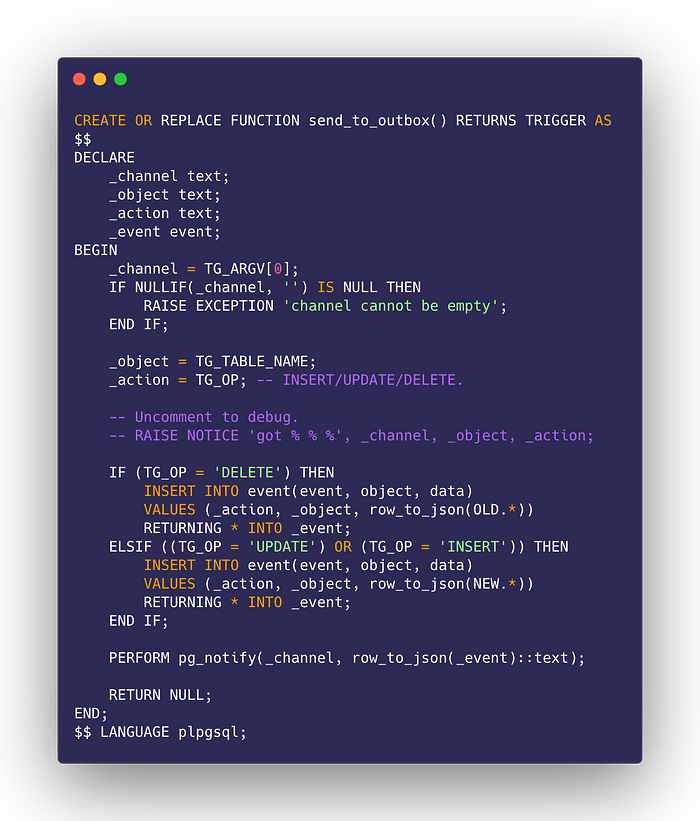
Basically, this step can be further simplified by creating a trigger that will be executed on INSERT, UPDATE, or DELETE. Assuming we have the following tables:
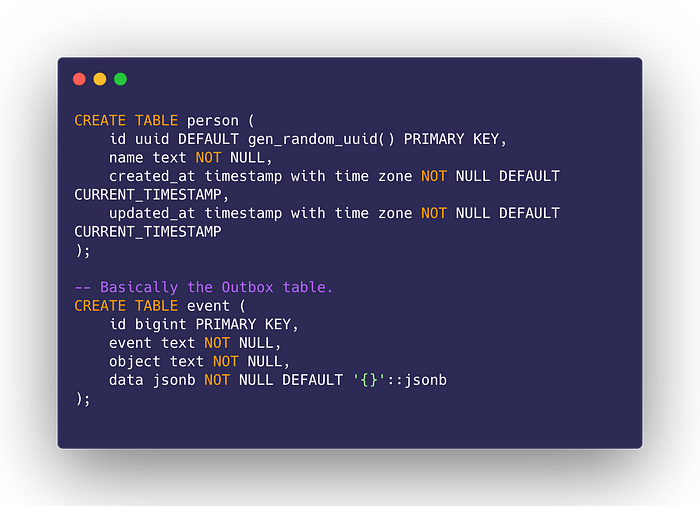
We can create a trigger that persists the event upon creation (the pg_notify is a bonus implementation):
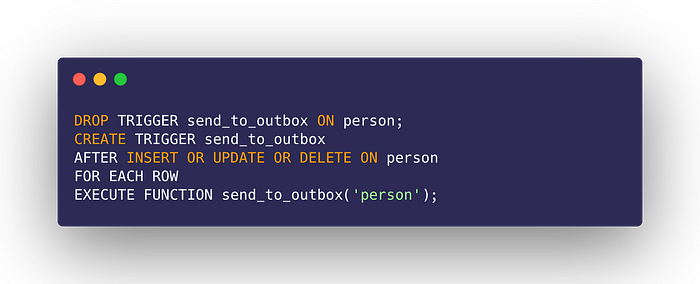
For each table that we want to attach the trigger to:
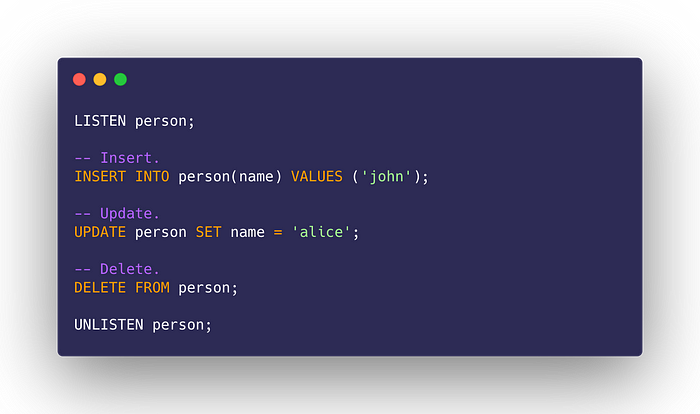
Testing it out:
However, it is not as flexible as performing the creation of an event in the transaction due to the following reasons:
- We can’t be granular with the event type, and representing the event as CRUD makes it hard when it comes to handling the event processing later.
- Triggers are less visible, compared to writing application code. Not all developers have access to creating triggers too.
- We now need to maintain triggers (adding, deleting, etc) for multiple tables (it’s not maintainable).
- The trigger assumes the event created is tied to the existing table, but it might not always be true. Say if we created an `Order` and wanted to send a user an email, but the event requires data from multiple tables, then we will have to query it later, at the risk of data changes. It would be safer to persist all those information as an event to be processed in the first place.
- We might one to publish multiple events in a single transaction if there are more operations involved.
Granularity of events
Back to the problem statement above — when the user registers for a new account, we want to perform the following:
- Send welcome email
- Send confirmation email
In other words, we have two event handlers for a single event UserRegisteredEvent. Keeping them idempotent and ensuring one-time delivery is tricky in this situation. In this case, we should actually split it into two events, WelcomeEmailRequested, ConfirmationEmailRequestedEvent respectively. This will ensure that there is only 1:1 mapping of the event to an event handler which simplifies the processing.
This idea is similar to having a queue of tasks, and processing them individually:
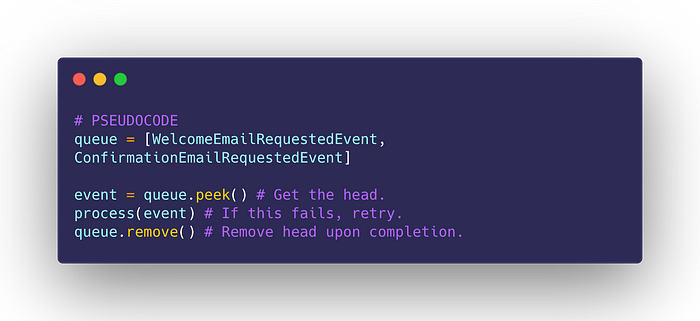
As opposed to this:

Of course, we can cache the steps in between, but caching introduce a few problems:
- how long to cache the intermediate steps?
- in-memory cache does not persist if a server restart
- distributed cache adds another dependency, as well as the complexity
By creating more granular events, we can also parallelize the processing further.
In other words, the proposed solution would be:
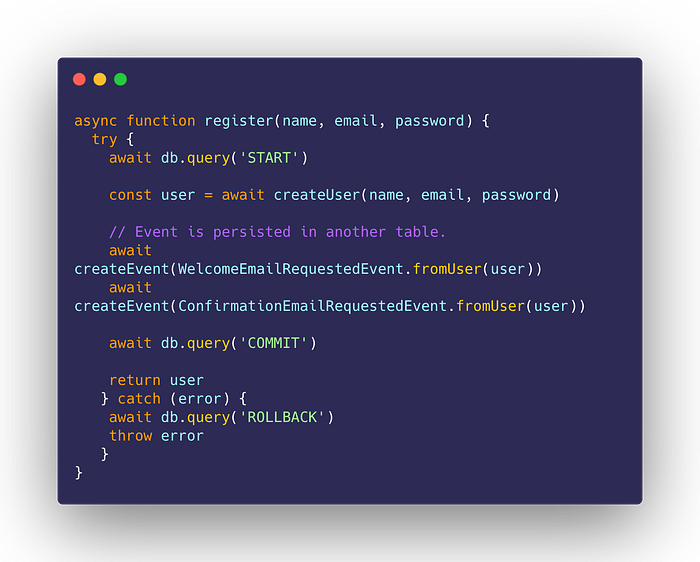
Batch vs Stream Processing
Above we demonstrated how to perform batch operations by pooling. Alternatively, we can also perform stream processing, by using listen/notify.
The differences are as follow:
- batch: we perform the operations in bulk. This is usually for processes that do not require real-time delivery.
- stream: we perform the operation close to real-time, on individual events.
The pool function is essentially a batch operation:

By processing the listen/notify, we can stream the event:

Our stream function handles only a single event at a time, and removing them from the database once completed:
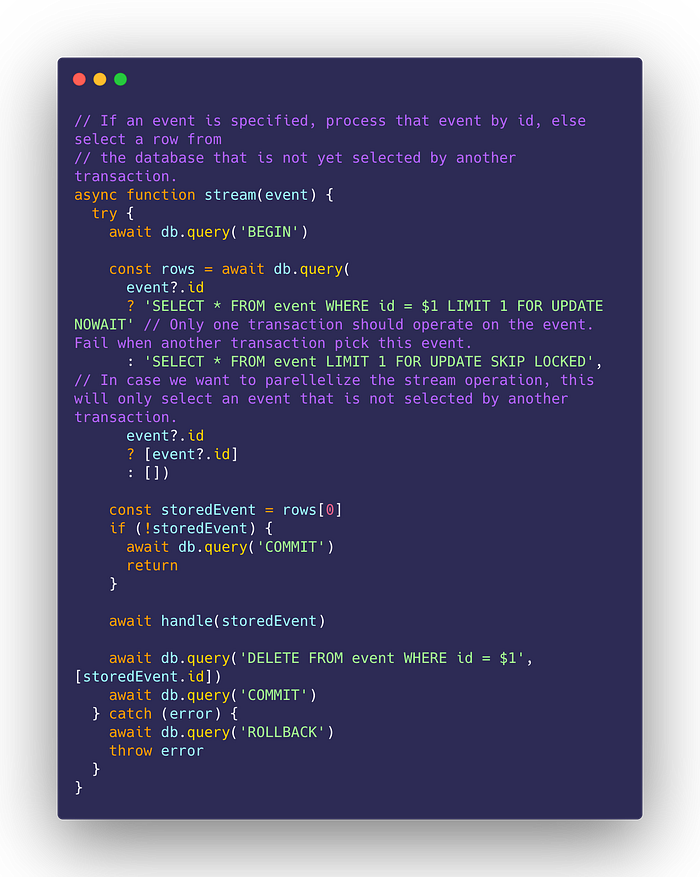
If the server restarts, we can always retry it by running the stream periodically to pick up on old events:
Parallelizing it is easy:
I hope you find this topic interesting.
